At a Glance
A production system for a construction company that does two things: answers internal-procedure questions with source-grounded, traceable answers, and turns a previously manual, multi-website weekly steel-procurement report into a ready-to-download Word document — automatically, in under three minutes.
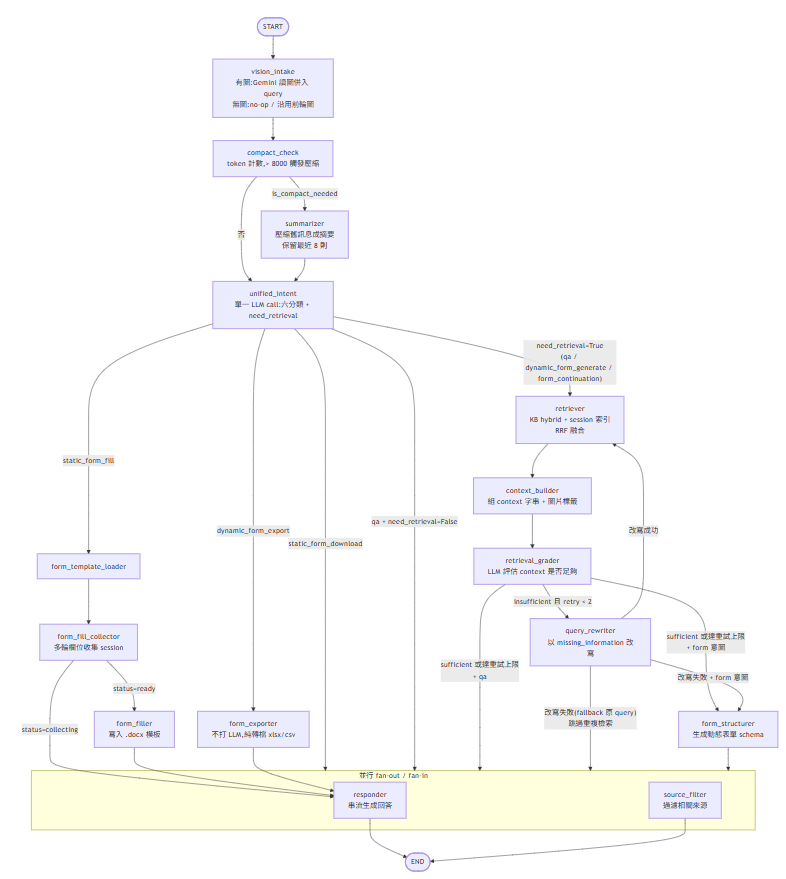 Construction assistant — system & graph flow
Construction assistant — system & graph flow
Why I Built This
The idea came from watching two very different kinds of friction inside the same company.
New and existing staff regularly need to look up construction procedures, regulations, and the right form for a given situation — but that knowledge lives scattered across dozens of internal manuals. Finding the right passage (and trusting it's the right one, not an outdated or similar-sounding one) takes time and institutional memory that new hires simply don't have yet.
On the procurement side, the pain was more concrete: every week, before a roughly 30-minute steel-purchasing meeting, someone has to manually visit five-plus external sources — Feng Hsin's weekly opening prices, international scrap and iron-ore indices, the Xiben mainland-China index, LME copper, China Steel's monthly/quarterly benchmark prices — copy the numbers down, compute week-over-week deltas by hand, write up a market narrative, and assemble it all into a Word meeting record. It's repetitive, easy to get wrong, and it eats real working hours every week before the meeting even starts.
Both problems share the same shape underneath: people spending time finding and assembling information rather than using it. That's exactly the kind of work an LLM agent — grounded in the right sources, with deterministic checks where it matters — is good at taking off someone's plate.
System Overview
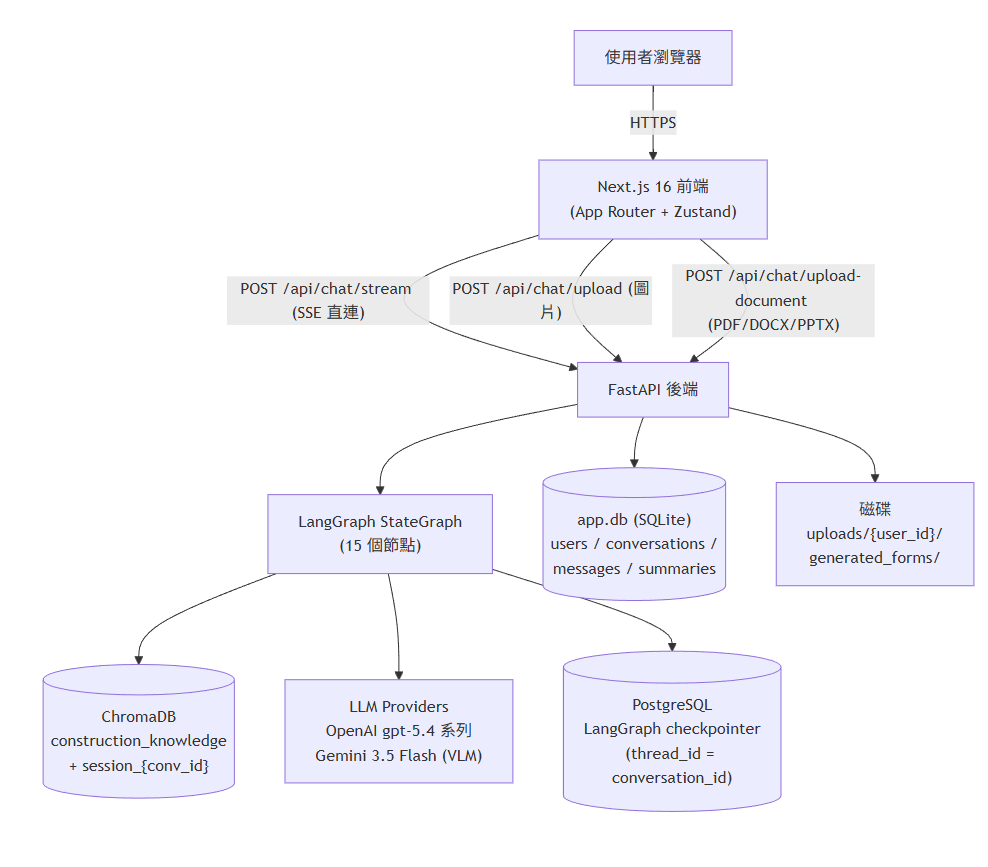 System architecture — browser → Caddy → FastAPI → LangGraph, ChromaDB, LLM providers and PostgreSQL
System architecture — browser → Caddy → FastAPI → LangGraph, ChromaDB, LLM providers and PostgreSQL
The system is a single FastAPI backend and a single Next.js frontend serving two modules behind one login:
- Module A — Knowledge Assistant (RAG): a 15-node LangGraph chat workflow that classifies intent in a single LLM call, runs hybrid retrieval over an internal knowledge base (51 construction documents, ~1,375 chunks), and grounds its answers in retrieved passages with visible sources. It also understands images (upload a site photo or a scanned form and ask about it), answers questions over documents you attach mid-chat (PDF/Word/PPT, chunked into a conversation-private vector index), accepts voice input, and can find/download static checklists, fill them out conversationally, or generate brand-new structured forms on the fly
- Module B — Steel Procurement Assistant (SEARCH): a separate LangGraph pipeline wrapped in a 6-step wizard — pick a meeting date → fetch live market data in the background (~90–180 seconds, so it never times out an HTTP request) → review fetched values and confidence levels → adjust China Steel benchmark prices → fill in internal meeting details → download the finished Word record
Both modules share the same FastAPI process, the same JWT-based authentication (with a fine-grained per-user permission flag gating the steel-price module), and the same Next.js bundle — but they're deliberately kept at arm's length: SEARCH has its own database and an explicit import boundary, so the two systems can keep evolving without breaking each other.
In production, everything runs behind PM2, fronted by Caddy, and exposed securely to the company over a Tailscale Funnel HTTPS endpoint.
Technology Choices — and Why
- LangGraph for both workflows, not a simple prompt chain — both the chat assistant and the report generator need branching (retrieve again? is this a form request?), retries, multi-turn state, and — for the report generator — the ability to run as a long background job that survives polling and page reloads
- Hybrid retrieval — ChromaDB vector search + BM25 with a 4,948-term construction-domain jieba dictionary, fused with Reciprocal Rank Fusion — pure vector search alone tends to miss exact-keyword hits that matter a lot in Chinese technical documents (clause numbers, form names, abbreviations); BM25 catches what embeddings smooth over, and RRF combines the two rankings without hand-tuning a blend weight
- PostgreSQL for all persistence (migrated from SQLite) — the project shipped on SQLite for zero ops overhead, but once it had real concurrent users and real schema migrations, SQLite on Windows became a liability (see below); everything now lives in PostgreSQL — three logical databases (
kb_app,kb_langgraph,kb_search) on one server — which closed an entire category of Windows/SQLite failure modes at the architecture level - Gemini 3.5 Flash for vision and speech, OpenAI gpt-5.4 for the main reasoning — one
get_llm()factory swaps the provider per node from config, so image OCR/description, voice input, and the chat responder each run on the model that fits them best - SSE streaming over FastAPI — chat needed to feel alive, token-by-token, not "spinner, then wall of text"
- Gemini with Google Search grounding, replacing a brittle authenticated web scraper for steel prices — when the scraper's underlying membership lapsed, I redesigned the fetch layer around an LLM that searches the live web and returns structured data, so the rest of the pipeline (price history, derived grades, Word rendering) didn't need to change at all
- python-docx for final output — the procurement team already works in a specific Word template; generating directly into that template means zero behavior change for them, just less manual work
- Next.js + shadcn/ui + Zustand/React Query — fast iteration, and a wizard-style UI that matches how the team already thinks about the weekly task: step by step, with a chance to review and correct each stage
Inside the System: Three Things I'm Proud Of
1. A self-correcting retrieval loop (CRAG). Retrieval doesn't always return good context on the first try — especially with vague or multi-part questions. So after retrieving and merging results, a "grader" model judges whether the retrieved context actually suffices. If not, a "query rewriter" reformulates the question and the system tries again — capped at two retries, so a hard question degrades gracefully into "best effort with a clear answer" instead of spinning forever. That loop is the difference between technically retrieved something and actually answered the question.
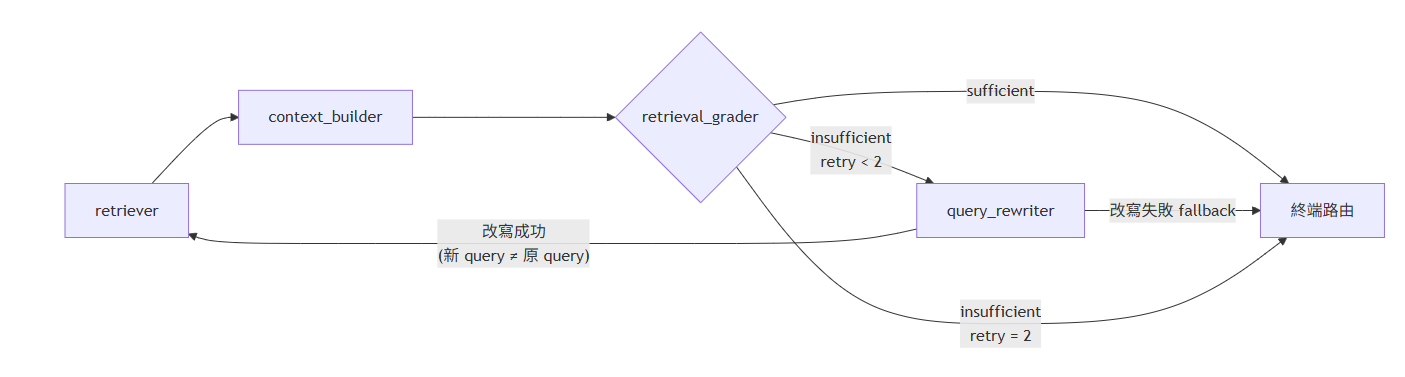 CRAG — retriever → context builder → grader → query rewriter, capped at two retries
CRAG — retriever → context builder → grader → query rewriter, capped at two retries
2. Keeping the LLM out of the arithmetic. The steel-price pipeline pulls numbers from several sources, computes week-over-week deltas, derives related grades (e.g. SD420W = SD280 + 1,000), converts currencies, and writes a narrative paragraph around all of it. It's tempting to just ask an LLM to "write up this week's report" — but LLMs are unreliable at exact arithmetic and prone to mixing up absolute values with deltas. So the system splits the work on purpose: the LLM handles search, structured extraction, and prose; every number that must be exactly right is computed in plain Python from validated inputs. Anything missing or unpublished is explicitly marked low-confidence (shown in red in the final Word document for human review), and "borrowed" stale values are displayed but never silently written into the historical price table — so the system never quietly corrupts its own ground truth.
3. One LLM call decides what every turn is. The earlier design was a brittle keyword-plus-LLM hybrid that misclassified short messages and grew an ever-expanding keyword list. Now each turn makes a single structured-output LLM call that picks one of six intents — Q&A, static-form download, static-form fill, dynamic-form generate, form continuation, dynamic-form export — and decides whether retrieval is even needed. Plain Python then guard-rails the result: a form id the model hallucinated, a continuation with no prior form, an export with nothing to export all fall back safely to Q&A, so a confident-but-wrong classification can never derail the rest of the graph.
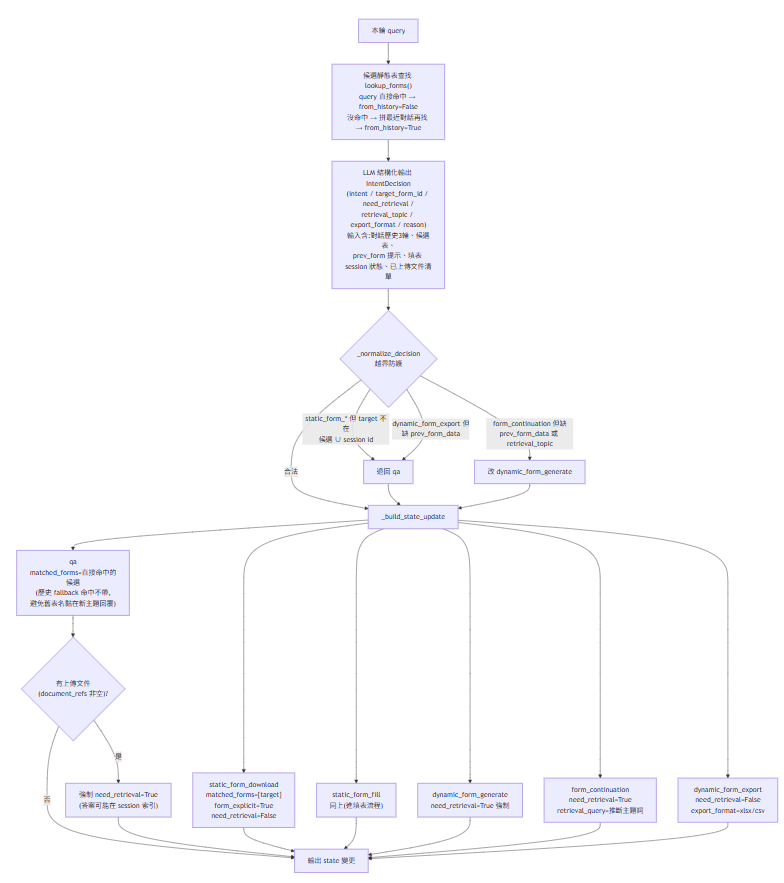 Unified intent — one structured LLM call, six intents, with code-level guard rails
Unified intent — one structured LLM call, six intents, with code-level guard rails
Challenges Along the Way
A few of the harder problems, and what they taught me:
- An Alembic migration nearly destroyed production data. Adding one column to the
userstable withbatch_alter_table(SQLite's way of altering tables: create a new table, copy rows, drop the old one, rename) silently triggeredON DELETE CASCADEacross the whole chain — wiping 52 conversations and 321 messages. The fix itself was simple (op.add_columninstead ofbatch_alter_table), but the real lesson was process: any migration touchingusers/conversationsis now treated as high-risk, with a mandatory timestamped backup and a dry-run in an isolated worktree first. This incident is also the single biggest reason I later migrated the whole system from SQLite to PostgreSQL. - A "ghost schema" bug from leftover SQLite WAL files. Restoring a database backup without also removing its
-wal/-shmsidecar files left new connections seeing a stale schema —alembicand thesqlite3CLI both reported the new column existed, while the app's async ORM insisted "no such column." It looked like a code bug; it was actually a filesystem one, and it took a while to track down precisely because of that mismatch (fix: delete the sidecar files after every restore). - Streaming that would randomly "freeze and dump." Chat responses occasionally stopped streaming token-by-token and appeared all at once after a delay — the classic symptom of something in the network path buffering the stream. The actual cause: Tailscale's routing config is globally overwritten, not appended to — any single command without the right flag could silently drop the
/apipath rule. I wrote a one-shot reset script and a short troubleshooting SOP, turning this from a confused half-hour into a two-minute fix. - A security tool that didn't trust my own deployment tools. The company's endpoint-protection software refused to trust Python processes spawned by PM2 or batch scripts, so the backend had to be started from an interactive terminal instead of being managed automatically — an annoying constraint I had to design the deployment process around rather than fight.
- An external data source quietly went dark. The site the steel-price scraper depended on required a paid membership that lapsed, breaking one of the system's core data feeds without warning. Rather than patch the scraper, I treated it as a chance to replace the whole approach — moving from "log in and parse HTML" to "ask an LLM with live web search for the same structured data," which is both more resilient to site redesigns and easier to extend to new sources later.
Results & Impact
- A previously manual, multi-site research-and-writing task now runs as an automated background pipeline that completes in roughly 90–180 seconds, leaving the team to review, adjust, and download rather than research and assemble from scratch.
- Performance work grounded in real usage, not guesswork. I optimized the hot paths directly — an LRU cache for embeddings (skipping repeat OpenAI calls on repeated queries), running vector and keyword search in parallel instead of sequentially, and moving the retrieval grader — one of the most frequently-called nodes — onto a smaller, cheaper model. To check whether that focus was right, I later built a token-cost analyzer over production LangSmith traces (~480K tokens across sampled threads): it confirmed that the responder and retrieval grader together account for the largest share of token spend — validating those earlier choices and pointing clearly at where the next round of optimization should go.
- Answers come with sources, not just text — every retrieved passage keeps its origin document, section, heading hierarchy, and even image references, so staff can verify an answer instead of just trusting it. That traceability matters more in a regulated, safety-conscious industry than a slick-sounding paragraph does.
- The system is in active internal use, served securely over HTTPS with role- and feature-level permissions — for example, the steel-price module stays opt-in even for admins.
Reflections & What's Next
Building two related-but-independent modules inside one shared process taught me more about boundaries than about RAG or LangGraph specifically — explicit import rules, separate databases, and "no cross-imports except through one mount point" turned what could have been a tangled merge into something I could reason about and roll back safely.
The SQLite incident was a hard lesson, but a useful one: a database choice that's perfect for "ship something that works" can become the wrong choice the moment you have real concurrent users and real schema migrations. Migrating the whole system to PostgreSQL (now done — three databases on one server) removed an entire category of Windows/SQLite-specific failure modes I'd hit more than once.
Image input is now live in the knowledge assistant — a vision-capable model in the loop, so staff can upload a site photo, a scanned form, or a diagram and ask questions grounded in that image, with multi-turn continuity so follow-up questions still know which image you meant. The trickiest design decision — dropping the carried-over image the moment a new document is uploaded, so "summarize this file" isn't hijacked by a stale photo — came straight out of a real bug.
Longer-term, I want to keep extending the steel-price source adapters as external sites inevitably change shape again — and keep applying the idea this project has now validated twice: don't make people assemble information by hand when an agent, grounded in the right sources and backed by deterministic checks where correctness matters, can do it for them.